A function operation is a procedure we can apply to transform or combine functions. Function operations are the essential tools that make mathematical modeling expressive. They are also the key to breaking complicated functions down into bite-sized pieces. The better you get at recognizing functions, and the richer your album of mental images, the more efficiently you will be able to break down formula into their pieces, visualize each piece, then visualize their combinations.
Linear Transformations...¶
to the Input: These transforms are used to generalize almost every distribution family. They need to be instinctive.
Horizontal Translation: Replace with to translate the function horizontally by a shift . For example, looks like shifted horizontally to the right by 3 units.

Dilation: Replace with for some to dilate the function. You can think of as controlling a zoom factor on the horizontal axis.
Using less than 1 compresses the function by making it narrower.
Using greater than 1 expands the function by making it wider. For example, setting makes the function three times wider.

If then the result also reflects about .
Generic: Replace with .
to the Output: We can apply the same operations to the outputs of functions.
Vertical Translation: Replace with to translate the function vertically by a height . For example, looks like shifted vertically by 2 units.

Vertical Scaling: Replace with to scale the function. You can think of as controlling a zoom factor on the vertical axis.
Using shrinks the function by making it shorter. For example, replacing with compresses vertically by a factor of 3.

Using expands the function by making it taller.
If then the function reflects about the horizontal axis.
Generic: Replace with .
Run the code cell below to visualize linear transformations of the inputs and outputs of a function. You’ve used this tool to check function properties. This time, experiment with the four sliders that perform horizontal translation, dilation, vertical translation, and scaling. Watch the grid lines in the background. These will translate, squash, and stretch, as you translate, dilate and scale. They represent the linear transformation of the original coordinate system.
from utils_week3_functions import show_function_properties
properties = show_function_properties()Function Combinations:¶
Algebraic Combination:
Function Addition and Multiplication: As they sound, or .
Visualize the function sums like a stacked plot where the two functions sit on top of one another.
Visualizing function products takes practice, and is often best left to the tools from Sections 3.1 and Section 3.3. When given a product, always check the roots and sign of each term separately. Unfortunately, many distributions are expressed as products of functions.
Linear Combination: This is a special version of function addition. It looks like for some coefficient and that scale each term in the combination.
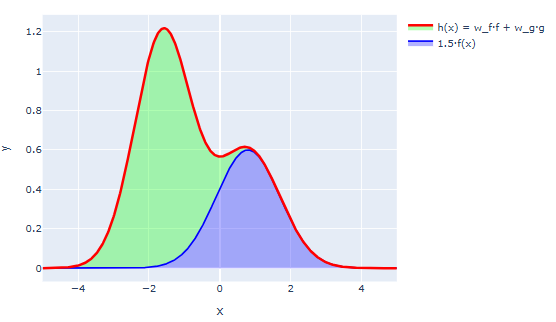
You can visualize a linear combination either by drawing its two component functions, and separately, then adding them together to produce the combo. The green and blue bumps are the component functions. The red curve is their linear combination. Varying or makes the associated bumps taller or shorter.
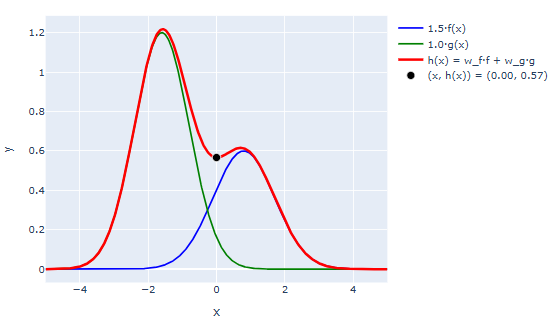
Alternately, you can use a stacked plot convention where you first draw , then you draw where the difference between your first curve and your second curve is . Here’s the same combination, using a stacked convention. In this example we drew the blue bump first, then added the green bump on top of it.
Important examples in probability are mixture distributions.
Mixture DistributionsTo construct a mixture, sample in stages.
For example, suppose that we have two large populations. We first pick a population to sample from at random, then, from that population, draw a sample of individuals. Then, we count the number of the sampled individuals who have a characteristic of interest and call our count . Suppose that, in the first population, 2 in 5 individuals have the characteristic, and in the second, 3 of 4 do.
This process can be modelled as follows. First, draw a Bernoulli random variable where is the chance we select the second sample population. Then, if , draw . If , draw . Note, these shouldn’t be exactly Binomial since we usually sample without replacement, but, if the population is much larger than , its not a bad estimate.
Then, what is the PMF for ? Well, we can find the chance that by partitioning, then using the multiplication rule. Alternately, draw an outcome tree. In either case:
Here is the PMF when we draw from the first population, and is the PMF when we draw from the second. The resulting PMF is a mixture of the two PMF’s since it is a linear combination of the two.
Here’s an example with and with . The colors represent the component distributions.
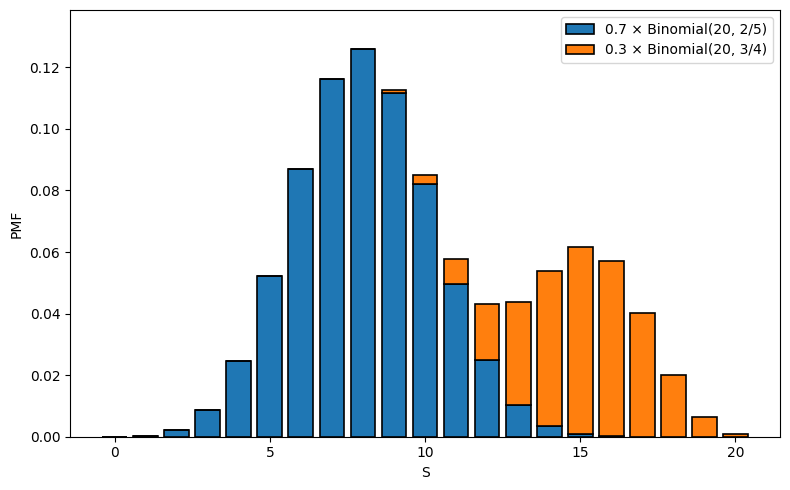
Run the code cell below to visualize function addition and multiplication.
from utils_week3_functions import show_function_combination
combination = show_function_combination()Function Composition: The composition of and is . Many distributions are expressed as compositions.
To visualize an arbitrary function composition, proceed as follows:
This process is a bit involved at first, but it’s a nice visual procedure. Once you get the hang of it, you can use it to very quickly evaluate compositions of arbitrary and . Just repeat the process for a bunch of different values. It is good practice to try this by hand at least once.
Run the code cell below to visualize the composition of two functions.
from utils_week3_functions import show_function_composition
composition = show_function_composition()The dashed orange lines represent the procedure provided above. Try building up an example composition. A good place to start is where the inner function is a negated quadratic and the outer function is an exponential. You’ll practice with this example in discussion.
Here’s a different example with with and .
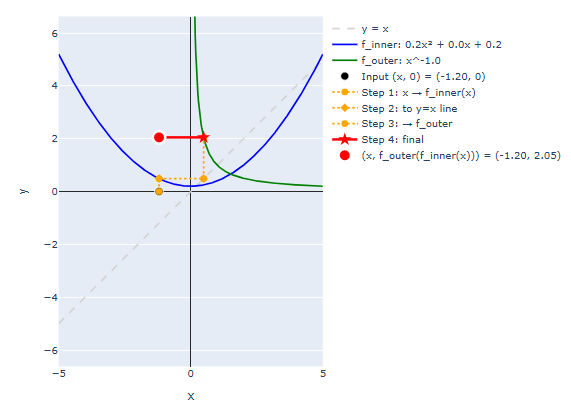
Building Distributions as Composites
These are both examples where the inner function is convex or concave, and the outer function is both monotonic and nonnegative. This recipe inner concave, outer monotonically increasing and nonnegative is a good procedure for building density functions. The outer function ensures that the composition returns a nonnegative number. It is usually selected so that it converges to zero in a limit that can be achieved by the inner function.
We can also use three-dimensional plots to visualize function compositions. Set the first axis to the input, , the second to the inner function, , and the third axis to the composition . If we plot as a function of , and as a function of , then we can recover as a function of .
As an example, run the code cell below. Set the inner function to . Set the outer function to .
Click “Show Inner” to show the quadratic function. Then click “Show Outer” to show the exponential function.
Then click “Compose” to reveal the composite (dark red). Move the cursor to vary the input .
from utils_week_4 import show_composite_3d
composition_3d = show_composite_3d()Inverses:¶
If is monotonic, then it is invertible. Its inverse, is the function that accepts outputs of and returns the matching input.
In other words, given , .
It can help to think, whatever does, undoes.
Inverse are constructed by reflecting about the line (exchange inputs and outputs).
To reflect, do the following:
The image below shows an example. The blue function if , the dashed grey line is the line that matches inputs and outputs, and the red curve is the inverse produced by reflecting across . The orange filled square is the square used to build the reflection.
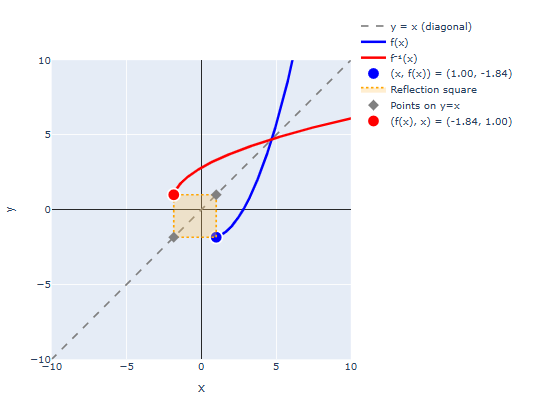
The most important examples in probability are the exponential and logarithm functions. Remember and .
Run the code cell below to visualize function inverses. Start with a linear function, and see how the inverse varies as we vary the initial function. The square you see represents the graphical construction outlined above. It is good practice to try this by hand at least once.
from utils_week3_functions import show_function_inverse
inverse = show_function_inverse()Once you’ve run the code below, go back to the composition demo provided above, and pick inner and outer functions that are related by an inverse. For example, and . Then, the graphical construction used to create the composite will trace the boundary of the reflecting square, always returning the corner. In other words, .
Applications of Inverses in Probability
Why care about inverses?
Inverse functions are extremely useful in applied problems. Here are two:
Finding Thresholds for Statistical Tests: It is common practice to run a statistical test by collecting some data, using it to compute a test statistic (e.g. the sample mean), then to compare the observed value of the test statistic to a threshold. Since data is almost always random, the observed test statistic is random, so we’ll denote it . We’ll denote the threshold . Often we pick the test statistic so that its value measures how much the observed data disagrees with what we would expect, or is typical, under some hypothesis. Usually, the larger the test statistic, the more evidence we have that the hypothsis is false. Formally, we pose a chance model for that should hold under the hypothesis. Then, we select the threshold so that, if the hypothesis were true, then for some desired close to zero. That way, if we observe , then the observed data would have been suspiciously atypical had our hypothesis been true. This is usually considered statistical evidence against the hypothesis. The chance, is the (inf)famous “p”-value.
The level controls how conservative, and how sensitive, our test is. You can think of it as the chance that the test falsely rejects if the hypothesis is ture. It is the level of evidence we demand in order to reject the hypothesis.
We usually start by fixing an (e.g. or ), then solve for the associated threshold . Notice that, . Then, our original equation was:
so, to find the desired threshold, we should use:
Sampling: Suppose that you wanted to draw a random variable with a specific CDF, . How would you do it?
Here’s an algorithm:
First sample a uniform random number . Most pseudorandom number generators due this by exploiting some of the properties of continuous random variables introduced in Section 2.3. Namely, if we draw some continuous random variable , then, no matter its PDF, if we drop the first digits of and multiply by then we’ll get a random variable between 0 and 1 that is essentially uniform if is big enough. Continuous random variables look uniform on sufficiently small intervals. In practice, many computers look up the time when you trigger a computation, drop most of the leading digits, then use the remainder to make a uniform number.
Convert the uniform random variable into the desired random variable via .
Why does this work?
Well, let’s find the CDF of :
All CDF’s are monotonically nondecreasing functions, so their inverses are also monotonic. Therefore: is the same statement as . Therefore:
Then, since is uniform we can use probability by proportion:
Notice, this will work for both discrete and continuous variables since it is based on the CDF, which is defined in the same way for both. We need to be a little more careful with our inverse definition for the discrete case, but there are no issues if we restrict the outputs of the inverse to the support of the target variable. This is the standard sampling protocol used by most random number generators.