Consider a pair of variables [x,y]. Suppose that f(x,y) is a surface. Then, the volume beneath the surface over a region R is defined by the double integral:
In Section 8.3 we saw that, if fX,Y is a density function for a random vector with two entries, then the chance a random vector falls in some region is defined as a double integral. Similarly, the expected value of a function of a random vector is defined as a double integral. In particular:
These observations generalize to more variables. For example, the chance a random vector with three entries lands in some region is expressed as a triple integral. In this chapter we will focus on the two-dimensional case. All results generalize directly to higher dimensions.
The uniform example worked above provides our first solution to a double integral.
You can compare this result to the same statement in one dimension. In one dimension, the integral of a constant over the interval is the constant times the length of the interval.
The same rule applies for double sums. The double sum of a constant equals the constant times the total number of possible index pairs used in the sum.
To evaluate general double integrals we use iterated integration.
Geometrically, iterated integration finds the volume beneath a surface by cutting the surface into cross-sections, evaluating the area under each cross-section then integrating the areas.
Note, we get to choose which variable to integrate over first. We can either integrate over y, then over x, or over x, then over y. This is an imprecise statement of Fubini’s Theorem. We won’t study the theorem formally in this class, but will use the result.
Usually we evaluate a double integral in three steps:
Pick an order. Choose the order so that the inner integral is easy to evaluate.
Suppose we chose to integrate over y first. Then, let R(x) denote the set of all y such that [x,y]∈R. You can picture R(x∗) as the interval formed by drawing the intersection of R with the vertical line at x=x∗. Evaluate:
Notice that, by iterating, we convert a single integration problem over two variables into a sequence of two integration problems, each with respect to a single variable. To evaluate each single integral, we can use any of the techniques we’ve learned before for integration of a univariate function.
Suppose that R is a rectangle. Then R={x∈[a,b],y∈[c,d]} for some a≤b and some c≤d. Often, rectangles are denoted using the shorthand, R=[a,b]×[c,d].
If R is a rectangle, then the range of available y is [c,d], no matter x. Similarly, the range of available x is [a,b], no matter y. So, the double integral can be expanded:
Run the code cell below to visualize a joint density surface as a three-D histogram. It will open the same demo we used in Section 8.3.
To help visualize this volume, try running the code cell below. Pick n=10. Then select “3D Perspective” and “Normalize by area”. Then, select the rectangular region R={x∈[0.20,0.50],y∈[0,1]}. You will see your rectangle highlighted with red boundaries.
from utils_joint_distribution import run_joint_distribution_demo
run_joint_distribution_demo()
Read the volume reported in the blue box at the bottom. Record the value.
Next, repeat the same experiment, computing the volumes for x∈[0.20,0.30], then for x∈[0.30,0.40], then for x∈[0.40,0.50]. Record each reported volume. Notice that each volume is the volume under a y-cross-section of the histogram.
Add up your three volumes. They will return the volume your originally computed for x∈[0.20,0.50]. This should be no surprise. The original volume was equal to the sum of the volume under every highlighted histogram bar. By adding over y with x fixed, then over x, you add over all the histogram bars.
This same logic applies no matter how small we make the boxes. It explains the iterated integral formula. Iterated integration is the same process we repeated above, in the limit as n goes to infinity.
Try making n large now. The reported volume is still the sum of the volume under each bar, and the collection of bars can still be added by first summing over y fixing x, then over x.
Suppose that [X,Y]is a continuous random vector supported on the entire x,y plane. Let fX,Y denote the joint density function of X and Y. What is the chance that X∈[1,b]?
We can approach this problem two ways. First, since our question only involved X, we can ignore Y, and work with the marginal density of X, fX(x). Then, as in Section 2.3 and Section 2.4, the chance X is contained in an interval is:
Alternately, the chance X∈[a,b] is the chance [X,Y]∈R where R is the rectangle with sides [a,b] and [−∞,∞] since this rectangle places no constraints on Y. Then:
Suppose that X and Y are uniformly distributed over the rectangle [0,1]×[0,2]. The rectangle has area 1×2=2, so the joint density equals 1/2 everywhere inside the support. Then:
Suppose that X and Y are independent variables. Then, as shown in Section 8.3, their joint density is the product of their marginals: fX,Y(x,y)=fX(x)×fY(y). So:
So, the product rule for double integrals recovers the product rule for independent random variables. Joint probabilities equal the product of the corresponding marginal probabilities:
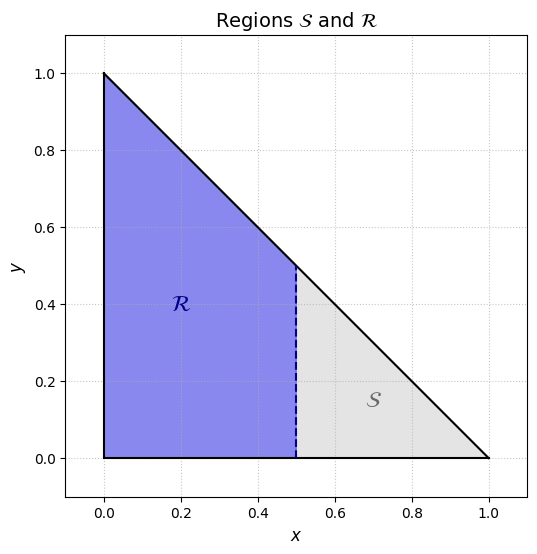
Let R={x≥0,y≥0,x+y≤1,x≤0.5}. The figure below shows the region R.
This region is a quadrilateral, with corners {[0,0],[0.5,0],[0,1],[0.5,0.5]}. It includes all x between 0 and 0.5. For any x∈[0,0.5] the range of available y is [0,1−x] since, x+y≤1 implies y≤1−x.
Pay careful attention to the bounds of the inner integral. When R is not a rectangle the bounds for the inner integral will depend on the outer variable. In this case, the upper bound for y depends on the choice of x.
To evaluate the double integral, first evaluate the inner integral:
Here’s a simpler way to work it out. Recall that, finding the area under a cross-section of the joint density, over the full range of the free variable returns a marginal density (see Section 8.3):
So, in our example, A(x)=fX(x), the marginal density of X. Then, borrowing our previous work, the random variable X is supported on [0,1] with marginal density:
The function g(x) is symmetric about x=1/2 since it treats x and 1−x equivalently. Therefore, X is a random variable whose distribution is even about x=1/2. It follows that the chance X<0.5 must match the chance X>0.5. Therefore, Pr(X≤0.5)=0.5.
Most integration rules also apply, by analogy, to summations. For example integrals of linear functions are linear functions of integrals. Sums of linear functions are also linear functions of sums. Integrals of products can be expanded with integration by parts. Sums of products may be expanded using summation by parts. Just as double integrals may be expanded as an iterated pair of integrals, double sums may be expanded as an iterated pair of sums.
Iterated sums expand a double sum as a sum over an outer index of a sum over an inner index, treating the outer index as if it were constant. For example, the double sum over i and j is the same as a sum over i of a sum over j given i.
Note that, as we saw for integrals, we can run the sum in either order. We can sum over i on the outside and j on the inside or i on the inside and j on the outside. We used this approach in Section 7.1 to derive the tail sum formula for expectations.
Here are two concrete ways to think about an iterated sum:
By Analogy to For Loops: If you implemented an iterated sum in code, you would use two for loops. The outer loop could run over all possible i. The inner loop would run over all possible j given i.
By Analogy to Table Operations: Suppose you were given a table whose rows are indexed by i and whose columns are indexed by j. Let f(i,j) denote the value of the i,j entry of the table. Then, a double sum over f is the same as the sum of a subset of the entries of the table. Summing over i, then j given i, is the same as using a sum over the columns, then a sum over the rows. Summing over j, then i given j, is the same as running a sum over the rows, then a sum over the columns.
For example, suppose that X∈{1,2,3,4} and Y∈{0,1,2} are discrete random variables. Then we can represent their joint distribution with a joint distribution table (see Section 1.4):
Joint
x=1
x=2
x=3
x=4
y=0
0.3
0.1
0.05
0.05
y=1
0.2
0.1
0.05
0.05
y=2
0.05
0.05
0
0
Then, the probability that X<3 and Y>0 is the probability that X∈[1,2] and Y∈[1,2]. Therefore:
![Support of [X,Y].](/notes/build/Support-0454ec33368404978ff59e3cc77702c9.png)