Another way to summarize the relationship between two variables is by fitting one variable to a function of the other. For example, we might look for the best fit line relating to . Then, the slope and intercept of the best fit will offer a summary of the relationship between and . Note: we are only summarizing the relationship with the fit line, not trying to use the fit to estimate some underlying relationship.
This makes sense when the two variables satisfy a roughly linear relationship. Here’s the example we introduced in Section 10.2 again.
from utils_cond_exp import show_conditional_expectation
show_conditional_expectation()In this case is a linear function of , so it is very natural to summarize the relationship between and with a line.
Finding a best fit line is an example of linear regression. We first considered linear regression in Section 9.3. We’ll recall the setting and result here, before reinterpretting the solution in terms of covariance and correlation.
Here’s an example linear regression problem using a least squares loss:
You are provided with a list of data points relating an independent variable to a dependent variable . These points form a scatter cloud in the plane.
You suggest a linear function that relates and , where and are free parameters.
You aim to find the best fit function among all by minimizing some loss function that measures the discrepancy between your proposed model and the observed data:
It is common practice to minimize the least squares loss:
where stands for mean square error.
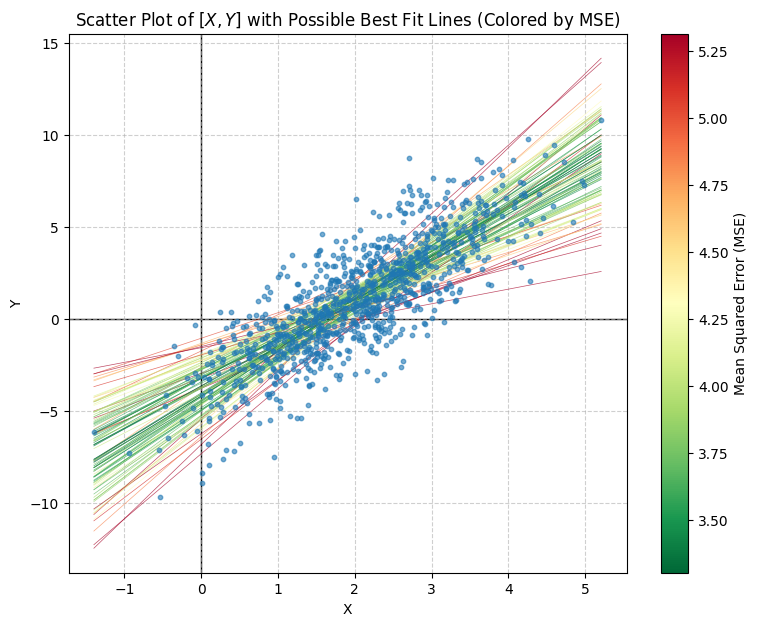
The figure below shows an example with 1000 sampled pairs (shown as blue scatter points). The lines represent 100 possible best fit lines (produced by fitting to 100 different bootstrap samples of 10 data points). They are colored according to the quality of their fit, as measured using mean square error (the least squares loss). The lines colored red are poor fits, and produce a large loss. The lines in green are good fits, and produce a small loss. Our goal is to find a formula for the intercept and slope that minimize the loss, so provide the best summary of the relationship between and .
Derivation
Let denote the vector of free parameters.
To find the best fit parameters, compute the gradient of the objective, and set it equal to zero. This suffices since the objective is a convex, quadratic function of the parameters, and we’ve placed no constraints on the parameters.
Here we’ve added the subscript to the gradient symbol to remind us that we are taking the gradient with respect to the parameters. Always pay careful attention to which variables you are optimizing over, and which are held fixed. In this problem the data is fixed, and we are optimizing with respect to the parameters of the model.
To compute the partial with respect to and we’ll apply the chain rule:
Then, since , and . So:
Setting the first entry to zero requires:
Rearranging, we need:
That is, the average value of the model must equal the average value of the data, . Substituting in for gives:
So:
Plugging back in, we find:
This is a nicer form. It ensures that the best fit line passes through the point where and are the average and coordinates in the data-set.
Now, can also be expressed more cleanly:
Let and . Then and are centered variables that represent a horizontal and vertical distance away from the mean. They correspond to the values of and had we started by centering our data (subtracting off the mean and coordinate). Many data processing pipelines start off by centering the data. Here we see a good reason to center your data when finding a best fit line. The best fit line automatically picks an intercept that effectively centers the problem. In terms of the centered variables:
So, the second entry of the gradient can be written:
The second term in the product is:
This term is zero since we chose so that the bracketed sum equals zero. To check our work, note that:
Both sums return zero since the variables and are centered.
So, the second entry in the gradient is:
Setting this entry to zero requires:
or:
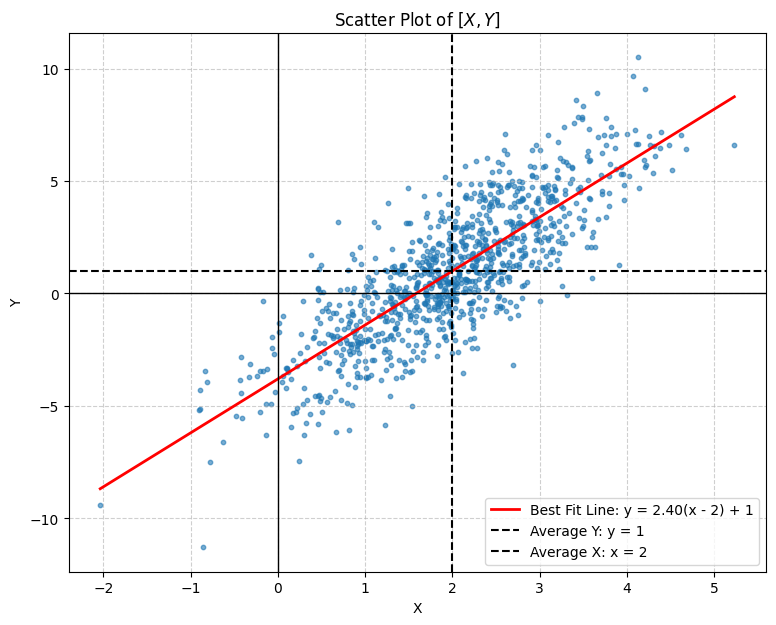
Here’s the resulting fit line (shown in red). The dashed black lines mark the empirical averages and .
Let’s try to make some more sense of this solution. First, since and are the empirical averages of the sampled ’s and ’s, if we rewtite the best fit line:
then we can express the best fit line in the centered coordinates:
This explains the best fit choice of intercept, . The best fit intercept is equivalent to centering the scatter cloud.
What about the best fit slope, ?
Consider its numerator and denominator separately:
These are an average product of the centered variables, and an average of the centered variables squared. In other words, the first has the form of a covariance (see Section 11.1) and the second has the form of a variance (see Section 4.3). These are the sample covariance and sample variance in the collection . They are equivalent to the covariance and variance if we choose and by picking an index, , uniformly at random from 1 to , then setting and . In other words:
If we use the empirical distribution, when , then we can write:
These equalities are exact if we use the empirical distribution. If, instead, are drawn from the background distribution, then these equations are approximates based on the observed samples. Regardless, if is very large, then the averages associated with the background distribution, and their empirical approximations, will be very similar. Taking to infinity will drive any approximation error to zero. So, from here on out we’ll think about this result as if and were sampled from the distribution that produced our data. We’ll study the sense in which empirical distributions and averages approximate the background distribution and averages against the background in Section 13.
We can now rephrase the best fit slope:
where the covariance and variance are their empirical approximations (finite ), or the true covariance and variance in and (infinite ).
Let’s rewrite this result in terms of the correlation. Recall that:
Therefore, the best fit slope is:
Let’s try moving all the terms involving to the left hand side. Then, the equation for the best fit line reads:
The fraction on the left is the standardization of . The fraction on the right is the standardization of . So, the best fit line relating two random variables is, after standardizing, the line, passing through the origin, with slope equal to the correlation between the variables. In other words:
So, we can view the slope of a best fit line, in standard units, and correlation, as identical objects. This is useful in two ways. First, it provides an easy procedure for remembering the best fit line formula. Don’t try to memorize the messy form we found originally. Instead, do the following:
Convert to standard variables.
Set the slope of the best fit line equal to the correlation in the original variables.
Convert back as needed.
Second, it provides a clearer interpretation of the correlation and its relation to linear associations. The correlation is a slope. It is a slope in standard units. This explains both why the correlation is not a good measure for nonlinear relations, and why the correlation is a natural measure of association for variables that share a rough linear relationship. It redefines the correlation, not as an abstract measure of association, but instead as the answer to a concrete question: “what is the slope of the best fit line to this dataset/distribution?”
So, to find a correlation graphically, translate your axes to center your data. Rescale the axes so that the data cloud has the same standard deviation in each dimension. Then, estimate the slope of the best fit line. The steeper the slope, the stronger the correlation.
This interpretation also recasts the role of a best fit line. The best fit line, to a collection of data points, or a joint distribution, is, like the distribution summaries introduced in Section 4, is just another way of summarizing a distribution. It’s intercept is fixed by, and represents, the empirical averages of the data. It’s slope, after standardizing, reflects the correlation in the sampled data points!