Objectives¶
Suppose that and are jointly distributed random variables. How can we summarize the relationship between and using their joint distribution? In particular, how can we summarize the degree of association between the variables?
Here’s an example. Run the code cell below. Suppose that and were drawn from the distribution displayed. Clearly and are related. The conditional distribution of given varies as varies. Increasing increases the chance that is large. As a result, the conditional expectation, is an increasing function of . Moreover, the conditional distribution of is considerably narrower, for every , than the marginal distribution of . That means that, if we observed , we could use our observation to make better informed guesses at than we could had we not observed .
from utils_cond_exp import show_conditional_expectation
show_conditional_expectation()How could we summarize the strength of this relationship between and ?
When defining a new mathematical object it can help to list out some desired characteristics or “desiderata”. Here are some natural desiderata for a measure of association:
It can also be helpful to identify desired “invariances”. These are ways of modifying a question that leave the answer unchanged. When measuring associations between and there are two natural invariances:
Covariance¶
Definition¶
Let’s try to design a measure that achieves all of our desiderata.
First, let’s work out how to ensure an invariance. We’ll start with invariance to translations.
To ensure that we treat and the same, for all , we could start by centering our random variables.
If we always start by centering our variable, then it doesn’t matter where it is centered to start. After centering it always has expectation equal to zero. So, centering will move all translations of the same distribution to the same distribution with mean zero. In particular:
for all possible .
So, to ensure invariance to translations, all we have to do is start by centering our variables. If we define our measure of association using centered variables, then it will be invariant to translations.
Since we will center every variable from here on out, it will be helpful to have shorthand notation for and . We’ll use and .
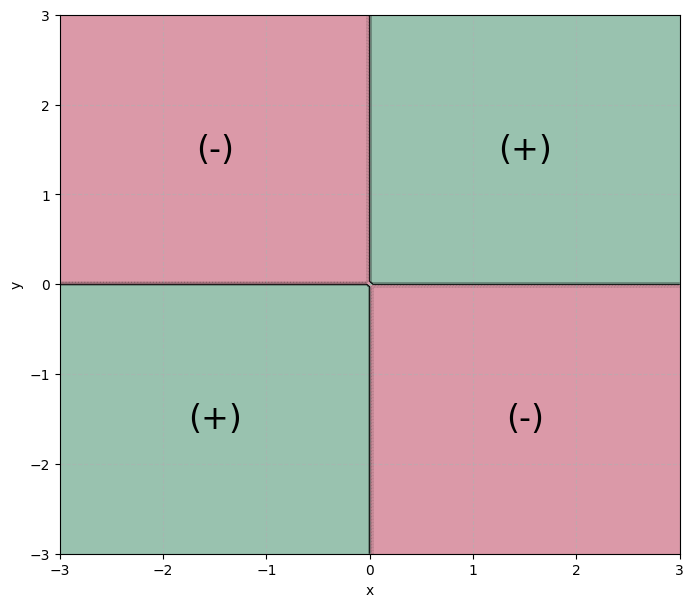
Next, let’s work on the second desiderata. Draw an plane. Mark the four quadrants.
Then, imagine sampling the centered variables and . The sampled pair, could land in any of the four quadrants. If:
and then both variables are larger than their expectation. This is evidence of a positive association.
and then one variable is larger than its expectation and the other is smaller. This is evidence of a negative association.
and then both variables are smaller than their expectation. This is evidence of a positive association.
and then one variable is larger than its expectation and the other is smaller. This is evidence of a negative association.
So, imagine coloring your plane, using green for quadrants (I) and (III) and red for quadrants (II) and (IV). Then label the green quadrants (+) for positive association and (-) for negative association.
Let’s look for a scalar valued function of and that is positive in quadrants (I) and (III), negative in quadrants (II) and (IV), and zero on the boundaries. A natural choice is the product function . Notice that:
If and then .
If and then .
If and then .
If and then .
So, is positive in quadrants (I) and (III), and negative in quadrants (II) and (IV). It is zero if either or are zero, so is zero along the coordinate axes dividing the quadrants. Here’s an overlaid heatmap + contour plot showing the function .
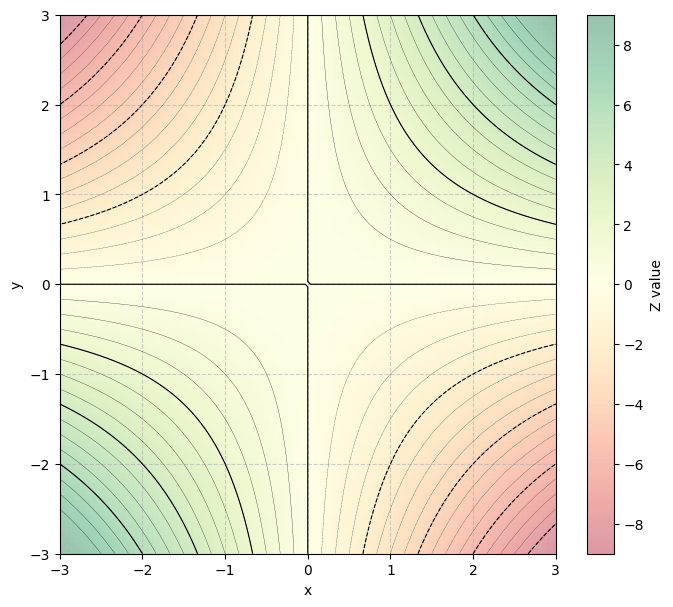
The function has another useful property that aligns to our desiderata. It increases in magnitude as either input increases in magnitude. So, if is far from zero, or is far from zero, then will be large. In contrast, if both are small, or one is much smaller than the other, then the product will be near zero.
Since we centered our variables, the origin represents the center of mass of our distribution. So, the function will be large when both variables vary far from their expectations, and will be small if both stay close to their expectations.
So, the function: is a natural measure for the degree to which a pair of sampled values jointly vary away from their expectations. In other words, it measures how much a single pair of samples “co”-vary. It is positive when the sampled vector suggests a positive association, negative when the sampled vector suggests a negative association, and is larger in magnitude the larger the variation.
Now, both samples are random, so their product, is also a random quantity. The degree of association between two random variables should be a number determined by their joint distribution, not a number that changes depending on a particular sample. So, to average over the possible values of and , let’s use the expected value of the product as our measure of association:
The expected product of the centered variables is the covariance in and .
The covariance in and measures how much the two variables vary together, e.g. “co”-vary. It is, by design:
Invariant to translations.
Positive when the variables are positively associated and negative when they are negatively associated.
Like variance, which is an expected square, the covariance, which is an expected product, is defined to give more weight to large joint variations than small variations.
Like expected values, or variances, covariances summarize an aspect of a distribution. In this case, the covariance summarizes how much the joint distribution associates positive deviations in one variable with positive deviations in the other.
Algebraic Properties of Covariance¶
Like any summary quantity defined as an expectation, the covariance has a variety of useful algebraic properties. Many of the algebraic properties of covariance are generalizations of the algebraic properties of variance. For example:
If either or are constants, then the covariance in and is zero since:
This is sensible. If one of the variables is constant, then it doesn’t vary. If one variable doesn’t vary, then the other variable can’t “co”-vary with it.
Covariance = expected product - product of expectations:
So:
This generalizes the formula for variance as an expected square minus a squared expectation. The covariance is the expected product minus the product of the expectations.
The algebraic properties of covariance generalize the algebraic properties of variance since variances are covariances.
So, the variance in a random variable is the covariance between the variable and itself.
Let’s check whether covariances are scale invariant:
So, covariances are not scale invariant. Instead, . For instance, . To find a scale invariant measure of association we will need to modify the covariance to eliminate its dependence on the units of and .
Correlation¶
Definition¶
What should we do to ensure scale invariance?
Think back to how we ensured translation invariance. We started by modifying our variable. Specifically, we proposed applied a transformation to standardize some aspect of the distribution. We translated the distribution to give it a standard expectation (expectation zero).
We can generalize this standardization procedure by translating, then scaling, our random variable. We will translate to give the random variable a standard expectation (give the distribution a standard center). Then, we will scale the random variable. Scaling a random variable dilates its distribution. We will scale so that the distribution has a standard width.
Recall the following definitions from Section 4.3:
The standardized variable is scale invariant since standardizing fixes the width of the distribution. To check, let’s standardize the variable :
where . So, as long as , the scaled variable produces the same standardized variable as .
So, to define a scale invariant measure of association, we will compute the covariance in the standardizations of and . The covariance in a standardized pair of variables is the correlation between the variables.
To compute the correlation in two random variables, standardize, then find the covariance:
so:
So, we can compute the correlation in two random variables from the covariance in the random variables and their standard deviations.
The correlation achieves all the desiderata and invariances described at the start of the chapter. Like the covariance it is translation invariant, its sign matches the sign of association, and is larger, in magnitude, the stronger the association between and . In addition, it is unitless, since standard variables are unitless. Therefore, it is scale invariant. It will not change if you change the units used to evaluate either or both random variables.
Interpretation as a Measure of Association¶
Because the correlation is unitless, and defined using standard variables, the value of the correlation can be interpreted on a standard scale.
The last point is important. It means that we can read correlation values and know immediately whether the variables are strongly or weakly associated. This is why we usually talk about the correlation between two variables, not the covariance, when we want to say they are strongly or weakly associated.
It is important that you develop an intuitive sense for large and small correlations. Navigate to this Correlation Guessing Game to practice guessing correlation values from collections of sampled pairs.
Geometric Interpretation¶
To prove that correlations are bounded between -1 and 1, and only equal -1 or +1 in the case when and must fall on a line, we’ll adopt a geometric interpretation of the covariance and the correlation.
First, to simplify our approach, imagine independently sampling pairs from the joint distribution for and . Then, let represent the vector of observed samples, and represent the vector of observed samples. Then, we could approximate the variances and covariances needed to compute a correlation with sample averages:
where:
are the empirical averages of the sampled and values.
These approximations are not exact, but will converge in the limit of infinite . We’ll go into more detail on the convergence of sample averages to expectation in the last chapter of the book (see Section 13). For now, as we have in previous chapters, we’ll take the relation on faith.
Now, examine the empirical variances. Each is, up to scaling by , a sum of squares of centered variables. Let and denote the centered vectors. Then, the empirical variance in the sampled values is the sum of all the entries of the centered vector, , squared, divided by . The sum of the squares of the entries of a vector is the square of its length (see Section 8.1). So:
Therefore, the empirical standard deviations are proportional to the lengths of each vector:
Next, consider the covariance. The empirical covariance is, up to scaling by , a sum, over every entry of and of the entrywise products. In other words, the empirical covariance is the inner product between and all divided by .
So, we can estimate the correlation between and with:
Cancelling the shared factor of :
Recall that, the inner product between two vectors equals the products of their lengths, times the cosine of the angle between them. Therefore:
where is the angle between the centered vectors of sampled and centered vector of sampled . This approximation becomes exact in the limit as goes to infinity, since, as goes to infinity, each sample average converges to an expectation against the background distribution.
We can use this interpretation to show that the correlation is bounded between -1 and 1, and only equals if and satisfy a linear relationship.
First, assume very large, so that the approximation is an equality. Then, for some angle . The cosine of any angle is bound between -1 and 1, so .
The cosine of only equals if or . In other words, the cosine of the angle between two vectors is only if the vectors point in the same, or opposite directions. In either case, the vectors must be parrallel. So, if and only if we can guarantee that the centered vectors produced by jointly sampling and , then centering, are parallel.
This requires or for some . Then, in terms of the original vectors of samples:
So, expanding elementwise, we need:
In other words, we need all but a vanishing fraction of the sample pairs to satisfy some linear relationship. We can only guarantee this if we can guarantee that for some slope and intercept and when are drawn jointly. In other words, the correlation in can only equal if is a linear function of .
The converse is also true. If for some and , then the correlation equals . You will check this fact on your homework.
Correlation and Dependence¶
The correlation in two variables is related to, but distinct from, the dependence or independence of the variables. Correlations look for a particular type of relationship between the variables. We will show in Section 11.2 that the correlation in two variables equals the slope of the best fit line in the standardized variables. As a result, if the variables depend on each other, but don’t share a linear relationship, they may be weakly correlated. So, weak correlations may not imply weak dependence. That said, if two variables are independent, then they cannot be correlated.
So, correlations (and covariances) satisfy the desired characteristic that, when and are independent, the correlation and covariance in and are both zero. It follows that, if , then and must be dependent variables. So correlated variables are dependent.
Beware. Uncorrelated variables may also be dependent.
Here’s another example where observing would provide information about , but, the two variables don’t share a positive or negative association so are uncorrelated:
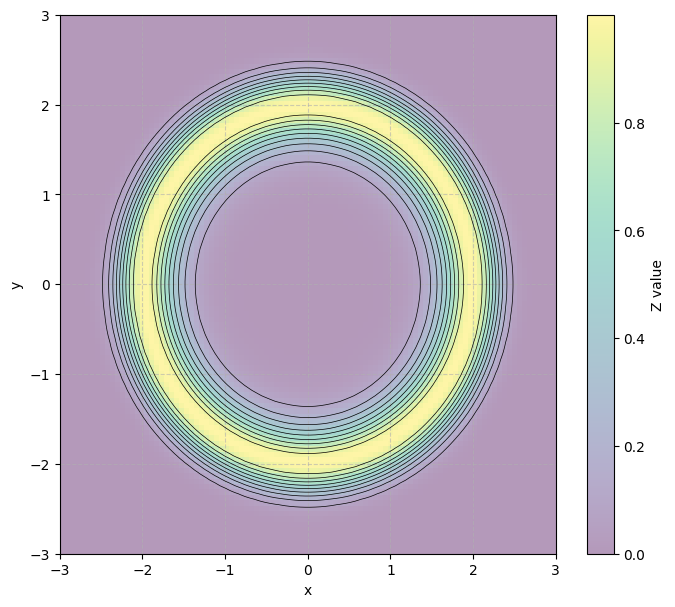
Remember: independent means uncorrelated, and correlated means dependent, but uncorrelated does not mean independent except in special cases (indicator variables or normal random variables).