We’ve shown that sample averages are guaranteed to converge to an underlying expectation provided the samples are sufficiently uncorrelated and are drawn with the same (or converging) expectations. We proved this result with an upper bound on tail probabilities for the distribution of the sample average. Unfortunately, the tail bounds used often overestimate the true tail probabilities. So, while strong enough to prove the weak law of large numbers, they are too weak to give useful finite sample guarantees when the user wants to guarantee accuracy with high probability.
Our results have been imprecise since we have avoided the exact distribution of the sum or sample average. This was useful since finding exact distributions is hard. We relied on summary quantites (e.g. expectations and variances) since these summaries were easier to compute and powerful enough to develop a general theory that applied no matter the original distribution. To improve on this theory we will need to study the actual distribution of long term sums and sample averages.
All examples and results in this section will pursue the exact distribution of a sum in a limit where the sum includes many terms.
Remarkably, the exact distribution of a sum, or sample average, converges, in the limit of infinitely many samples, to a normal distribution, regardless the original distribution used to generate the samples.
This theorem is the last major result in most introductory probability classes. It is especially useful when we want to produce confidence intervals. It suggests much tighter intervals than the tail bounds developed in Section 13.2. It explains the ubiquity of the normal distribution in applied probability and probability modeling.
Suppose that {Xj}j=1n are drawn independently and identically from a Bernoulli distribution with success probability p.
In this case we can write down the distribution of Sn exactly. The sum, Sn=∑j=1nIj, is a sum of independent, identical indicators, so is drawn from a binomial distribution with parameters n and p:
Since we have a closed form for the PMF of the sum, we can study the limiting distribution of the sum directly. Run the code cell below to visualize the binomial distribution. Choose some p and hold it fixed. Then gradually increase n.
from utils_dist import run_distribution_explorer
run_distribution_explorer("Binomial");
You should notice three main effects:
As you increase n, the peak in the distribution slides to the right. We’ve known this for a while. The expected value of a binomial distribution is, by additivity of expectation, np, and its mode is close to np. So, the peak of the distribution will move rightward along the line np as a function of n.
The distribution gets wider as n increases. We proved this in Section 13.1. The variance in a sum of independent, identical random variables grows proportionally to the number of terms in the sum. So, the standard deviation in Sn will grow proportionally to n. Using our rules for the variance of a sum, SD[Sn]=np(1−p).
Notice, the standard deviation grows slower than the mean (O(n1/2) vs O(n)). So, if your axis adjusts to fit the bulk of the distribution, the distribution may appear to grow narrower as n increases. Pay attention to the marks on the x-axis. The distribution is getting wider as n increases.
The distribution becomes more and more bell-shaped.
The last observation is the remarkable one. It is true for the sum of any Bernoulli random variable with p=0 or 1. It would also be true had we used essentially any distribution to sample the X’s!
The function for the bell-curve you are seeing is given by the normal curve with mean μ=np and standard deviation σ=np(1−p):
A random variable with density of the form provided above is a normal random variable. You can experiment with normal random variables by running the code cell below. Note that the normal curve has the same shape as the bell shaped histogram we observed for the binomial with large n.
from utils_dist import run_distribution_explorer
run_distribution_explorer("Normal");
We proved that the binomial does, in fact, converge to the normal curve at the end of Section 6.4. There, we assumed that p=1/2, and proceeded with a detailed limiting analysis based on Striling’s formula (see Section 6.3).
For now, we will accept the claim based on the observation that the plotted histogram, and plotted curve, look suspiciously similar. We will recapitulate our old proof at the end of this chapter. We save the proof since the specific limiting analysis depends on details of the binomial PMF.
Our goal now is to see that we would arrive at the same normal curve, from any initial distribution. Since we can’t test all initial distributions, we’ll try a different test case.
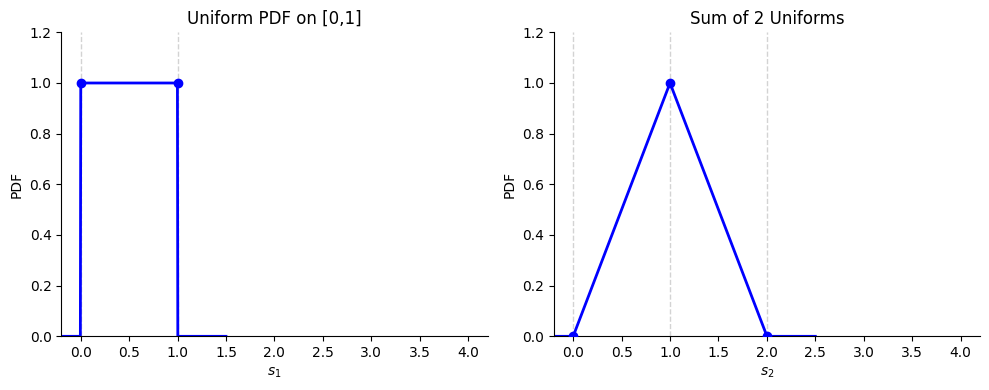
The simplest discrete case is Xj∼Bernoulli(0.5). This is a uniform distribution on the set {0,1}. Let’s try the simplest continuous analog, Xj∼Uniform([0,1]). Then Xj∈[0,1] for all j and:
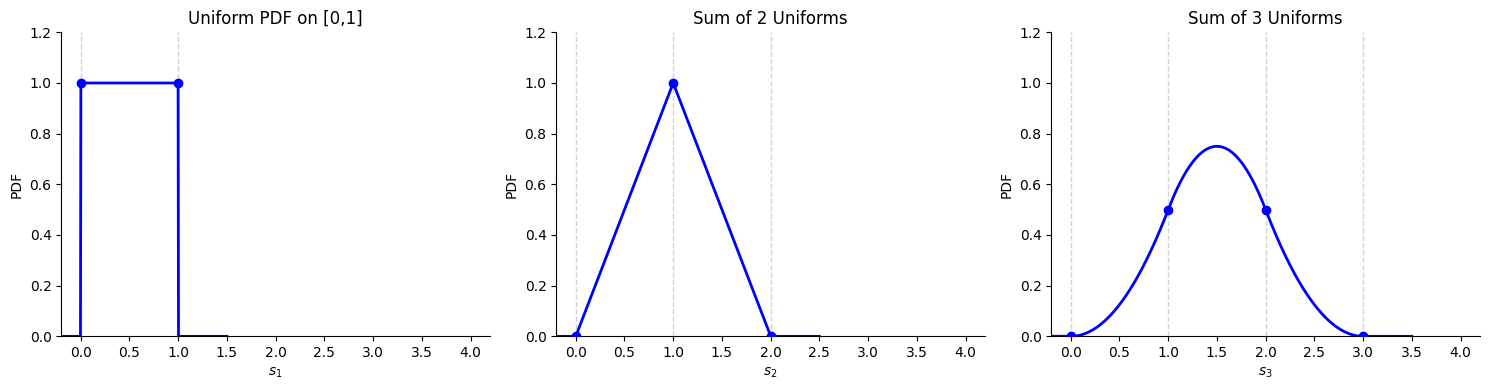
So, to find S3, we need to compute [fS2∗fU](s). Since both densities are defined piecewise, the resulting density for S3 will also be defined piecwise. We can work out the boundaries between pieces as follows:
S3<0 is impossible since S3 is a sum of nonnegative variables.
S3∈[0,1) requires S2<1 since X3 is nonnegative.
S3∈[1,2] allows any S2∈[0,2].
S3∈(2,3] requires S2>1 since X3 is less than one.
S3>3 is impossible since S3 is a sum of three variables, all less than or equal to 1.
The first and fifth observations fix the support, S3∈[0,3]. The middle three observations divide the support into three intervals, [0,1),[1,2],(2,3].
So, to find the density function, we should run convolution separately on each interval. To see the explicit convolution, open the drop down below.
Convolution
We’ll work out the convolution one interval at a time. We’ll do the outer intervals first since the distribution of a sum of uniform random variables is symmetric about its expectation (the distribution of 3−S3 is the same as the distribution of ∑j=13(1−Xj), which has the same distribution as S3=∑j=13Xj since Xj and 1−Xj are identically distributed when Xj is drawn uniformly on [0,1]).
This is the downward facing parabola, centered at s3=1.5, that equals 1/2 at s3=1 and 1/2 at s3=2.
After convolving, we find that fS3(s3) is a piecewise function that is:
zero outside [0,3],
an upward facing parabola centered at zero connecting (0,0) to (1,1/2),
a downward facing parabola centered at 1.5 connecting (1,1/2) to (2,1/2),
then an upward facing parabola centered at 3 connecting (2,1/2) to (3,0).
Reading in order, the density function is constant and zero, curves up, curves down, curves up, then is constant at zero again. The result is a symmetric bell centered at 1.5. The central location is sensible since E[S3]=3E[Xj]=3×21=1.5.
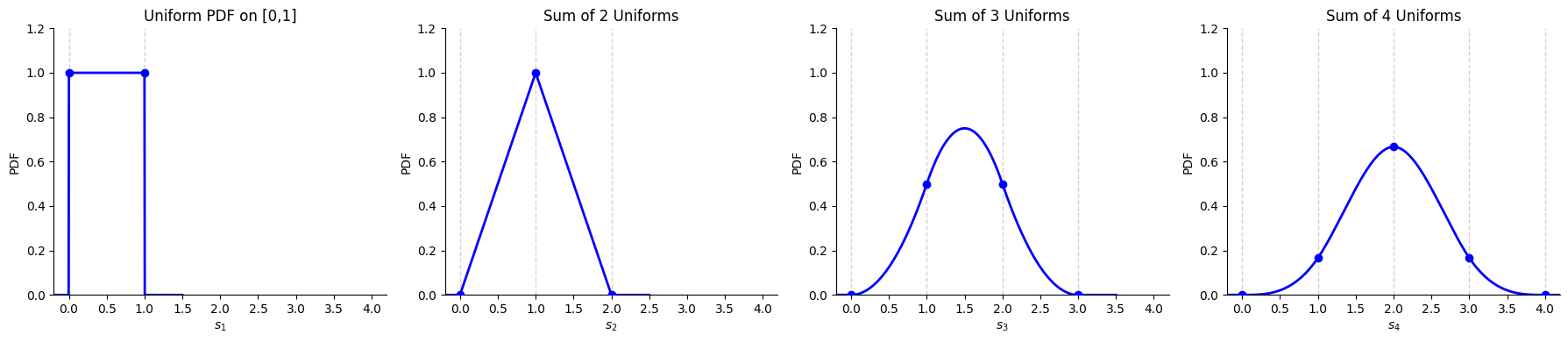
Clearly, this procedure is too involved to continue by hand. Nevertheless, the graphical trend is clear:
S1 is drawn from a box shaped distribution
S2 is drawn from a tent shaped distribution
S3 is drawn from a bell shaped distribution (with parabolic pieces)
It should not be too surprising that, if we keep going, the resulting distribution becomes a smoother and smoother bell. Here are the first four densities:
The last density is very bell shaped! It is a symmetric, piecewise density, centered at 2, with three pieces, all cubic functions of s3.
First, let’s recall the definition of a normal random variable (see Sections 5.4 and Section 6.4).
To make this statement formal, we need to adjust it in two ways. First, we need to define what we mean by convergence.
What do we mean by convergence?
We will say that a sequence of random variables {Yn}n=1∞ converges in distribution to a limiting variable Y if the cumulative distribution function of Yn converges to the cumulative distribution function of Y. We use the CDF to avoid finagling over the difference between density and mass functions. Then, we can guarantee that, for any interval, [a,b]:
The same conclusion extends to finite collections of disjoint intervals so ensures that any answer to a probability question we might ask about Yn can be approximated with an answer using Y provided n is sufficiently large.
Second, we need to change to standard variables. Neither the sum, nor the sample average admit sensible limiting distributions since the expectation of the sum diverges, while the variance of the sample average converges to zero.
Go back to the binomial example. The distribution of Sn slides rightward while widening as n increases. So, Sn doesn’t approach a random variable drawn from any fixed limiting distribution.
The sample average, Xˉn, behaves more nicely. Its mean stays planted at μ for all n. However, as we increase n, the distribution of the sample average concentrates, so SD[Xˉn] converges to zero. Therefore, if Xˉn approaches a limiting variable, the limiting variable is deterministic, limn→∞Xˉn=μ. So, Xˉn does not have an informative limiting distribution either. It’s limiting distribution has infinite density at μ and is zero everywhere else.
To get a sensible limiting distribution we need to find a transformation of Sn and Xˉn whose mean and standard deviation converge to sensible values as n diverges.
Graphical Intuition
You can think about this graphically. The standard bell-curve we keep seeing is produced by plotting the distribution, then centering our plot to center the bell at zero, and scaling the x-axis so that the axis limits fit most of the bell. The first step is a centering step. It keeps the mean fixed at zero. The second step is a scaling step. It chooses an x-axis scale so that the bell stays the same width. These are the steps needed to standardize a random variable (see Sections 4.3 and 11.1).
The central limit theorem applies regardless the underlying distribution producing the samples. However, the specific limiting construction matters.
For example, we saw in Section 6.4 that the limit, as n diverges, of a binomial distribution with parameters n,pn=λ/n converges to a Poisson distribution, not a normal distribution. In this case, the limit is Poisson since the success probability is vanishing as n increases. The central limit theorem assumes that the distribution used to produce the samples stays fixed as we increase n.
Similarly, the way in which we combine the n samples matters. If we’d taken a sample maximum, instead of a sample average, then the limiting distribution would not be normal. Instead it would have been drawn from a generalized extreme value distribution.
Suppose that {Xj}j=1n are independent, identically sampled Bernoulli random variables with unknown success probability p. Then, the maximum likelihood estimator for p is the sample average:
The sample average is the observed frequency of success in the n trials.
If n is large, then p^ is a sample average of a large collection of independent, identical samples. So, it is approximately normally distributed with mean E[Xj]=p and variance n1Var[Xj]=n1p(1−p).
So, as long as n is large, the probability that the observed frequency differs from the true success probability by more than k standard deviations is, approximately:
The probabilities that a standard normal random variable is larger, in magnitude, than an integer k are well-known. We’ll compare them to the upper bounds produced by Chebyshev’s inequality (see Section 13.3)
k
1
2
3
Chebyshev
1
1/4
1/9
CLT
0.32
0.05
<0.01
Notice how much smaller the tail probabilities suggested by the CLT are than the upper bounds provided by Chebyshev. It follows that, when the assumptions of the CLT apply, the tail probabilities for a sample sum or sample average will often be much smaller than the Chebyshev bounds.
So, for sufficiently large n, the chance that the observed frequency is within 2 standard deviations of the true chance converges to about 95%, and the chance it is within three standard deviations of the mean converges to about 99.7%:
This example illustrates the power of the CLT. The CLT allows us to approximate exact tail probabilities in the limit of a large sample size, regardless the initial distribution that produces the samples! It also explains the folk wisdom, “When estimating an unknown quantity, your result is probably accurate within ± 2 standard deviations.”
We are not equipped to prove the CLT for arbitrary distributions. If you’d like to see the general proof, take a second course in probability (e.g. Data 140 or Stat 134).
We will satisfy ourselves with some specific cases where we can perform the limiting analysis directly. We completed the first case in Section 6.4.
The constant 2/n out front is the interval between successive possible values of Zn. We’ll call this gap Δzn. To convert to a density function, we will divide out by Δzn. Dividing by Δzn cancels the 2/n term. For details, check the dropdown below.
Conversion to a Density
The standard normal random variable, Z, is continuously distributed, so is parameterized by a density. Each Zn is a discrete random variable. To recover a density from a probability, we need to divide out by the length of an interval.
In this case we can construct a density from Zn by replacing Zn with a random variable Wn, where Wn∣Zn=z∼Uniform(z−Δzn/2,z+Δzn/2) where Δzn is the gap between successive possible values of Zn. Since Zn=n1(2Xn−n), and Xn are integer valued, Δzn=n2.
Representing the PMF of Zn with a bar plot. The widths of the bars is Δzn.
Scaling the height of the bars by their widths so that their area returns the PMF value. The height of the scaled bars return the density function for Wn.
Integrating over the density function of Wn, with bounds equal to the endpoints of the bars, will sum over the PMF of Zn. So, all probability questions we could ask about Zn could be answered by integrating over the density function of Wn.
Now that we’ve handled the normalizing constants, focus on the functional form:
The expression on the left is a PDF since Δzn converges to zero as n diverges. The expression on the right is the standard normal density function. Therefore:
If you like challenging algebra exercises, try the same limiting analysis for generic p. The steps are all the same, but you will need to pay careful attention when you standardize and when you apply Striling’s formula.
Let’s try a continuous example. The uniform case is hard, so we’ll pick the next simplest example, exponential random variables.
Suppose that {Xj}j=1n are drawn independently and identically from an exponential distribution with parameter λ.
In this case, we can work out the distribution of the sum Sn exactly using convolution.
Run the code cell below to visualize the convolution of two exponential random variables. Select exponential for both distributions, then match their parameters.
%matplotlib inline
from utils_convolution import show_convolution
show_convolution()
The distribution you’ve produced has density function:
You worked out the result for general n on homework 12. For the necessary work, check the matching solutions. The sum is gamma distributed with shape parameter n and rate parameter λ:
Experiment with gamma distributions by running the cell below. Start with shape = 1. This returns an exponential random variable. Then increase shape to 2. This produces the gamma distribution of S2. Then gradually increase the shape parameter. As you do, you will see the distribution shift to the right and become gradually more bell shaped. It remains skewed, though the skew decreases as the shape parameter increases. The mean of the distribution, which lies to the right of its mode, increases linearly in n.
from utils_dist import run_distribution_explorer
run_distribution_explorer("Gamma");
Next, convert to a standard variable. To standardize, we need the expectation and variance in the sum. Both follow from our usual rules for expectations and variances of sums (see Section 13.1). The expectation and variance of an exponential random variable are 1/λ and 1/λ2 (see Section 7.1).
To find the density function of Zn, use the linear change of density formula from Section 7.2. Set h(s)=nλs−n. Then h′(s)=nλ and h−1(z)=λn(z+n). Then:
Thus, the normalization constant converges to the normalization constant of the standard normal, 1/2π. Open the drop-down below for the step-by-step analysis using tools from Section 6.
Limiting Analysis of the Normalization Constant
To simplify the leading term, we’ll use Stirling’s formula (see Section 6.3):
In this case it will be easier to work out the limit of the logarithm of the functional form. Since the log is continuous, the limit of the logarithm is the logarithm of the limit. So, we can find the original limit by taking the limit of the logarithm, then exponentiating our answer.
Since z/n is small when n is large, we can replace the logarithm with its Taylor expansion near zero (see Section 6.1). In this case we will need to go past our usual linear approximation to the log and include quadratic terms: